Robust Speech Recognition via Large-Scale Weak Supervision
(WSPSR: Web-scale Supervised Pretraining for Speech Recognition)
💡OpenAI에서 발표 강건한 음성인식 모델로 noisy한 데이터를 보완하기 위해 많은 튜닝과 휴리스틱을 사용한 것이 특징이다. 공식 코드와 모델 가중치가 제공되고 있으며 지금까지도(2023.02.26 기준) 활발히 기여가 일어나고 있다.
공식 코드
- https://github.com/openai/whisper
- 아주 훌륭한 성능의 음성인식/음성번역(영어) 모델
- 음성인식시 timestamp 제공
논문의 의의/기여
- Robust model for OOD dataset & noise
- Multilingual & multitask model
- 실험 논문(Ablation)으로서의 기여
1. Introduction
Unsupervised pre-training vs. Supervised pre-training
Wav2Vec 2.0 의 등장 이후 음성인식 분야에서는 Unsupervised pretraining 방식을 사용하는 모델이 많이 나왔다. 하지만 Whisper 저자들은 음성 인식은 어떤 상황에서도 reliable 해야 하며, 매 상황에 따라 디코더를 fine-tuning할 필요가 없어야 한다는 문제 의식을 가지고 Supervised 모델을 제안한다.
| Unsupervised pretrained model | Supervised pretrained model | |
|---|---|---|
| 장점 | raw audio로 학습해 더 좋은 피쳐 학습 | end-to-end로 한 번에 음성인식이 가능한 모델 학습 |
| unlabeld data로 학습해서 scale up하기가 쉬움 | 학습된 모델을 가져다 사용하면 됨(practitioner 필요 없음) | |
| 단점 | 인코더처럼 고성능을 내는 디코딩 매핑이 없기 때문에 fine-tuning 단계를 거쳐야 함 → fine-tuning을 하려면 이런 복잡한 과정을 아는 practitioner 필요 | labeled data가 필요하기 때문에 scale up 하기 어려움 |
| fine-tuning할 때 사용하는 데이터의 패턴에 따라 다른 데이터셋에 적용시 일반화 성능 떨어짐 |
본 논문에서 제안하는 해결 방안
- 다양한 데이터셋과 도메인의 데이터를 사용해 강건하고 일반화 성능이 높은 모델 만들고자 함
- 한계: Supervised dataset은 규모가 작음 (5140H - SpeechStew)
- 해결: Weakly supervised Speech recognition 데이터 사용
weakly supervised dataset
- Noiser(low quality) training data
- Traditional supervised learning보다 큰 사이즈
기여
- weakly supervised pretraining을 스케일업(680,000H)
- Supervised 모델과 Unsupervised 모델의 데이터셋 크기 간극 줄임 (unsupervised의 100만 시간 vs. 기존 supervised의 5140H)
- 큰 모델의 경우 multilingual & multitask 로 학습하는 데서 얻는 이점 있음
- Fine-tuning 없이 fully-supervised model과 비슷한 성능
2.1 Data Processing
- Pre-processing은 적게 함
- Seperate inverse text normalization만 함
- Inverse text normalization(ITN)
- ITN: Numbers, dates, times, addresses 등 formatting하는 작업

데이터셋 구축 💫
인터넷에서 찾은 오디오-대본 쌍 사용 -> 퀄리티가 일정하지 않기 때문에 automated filtering 사용
1) ASR 모델이 만든 대본 제거 - 이를 감지하기 위해 여러 휴리스틱 사용 - ASR 결과에 쉼표 없음, 모두 소문자, 문장부호나 단락 구분 생략된 경우 등
2) 언어 감지 → Spoken language와 대본의 언어가 일치하지 않으면 제거
3) 중복 데이터 제거
Segmentation
- 오디오 파일을 30초 길이로 자른 후 그 구간 내 대본과 연결
- Speech가 없는 세그먼트는 VAD에 사용
데이터셋 필터링 💫
- 모델 1차 학습 후 학습데이터의 소스에 따른 error rate를 계산
- 데이터 소스 사이즈와 error rate에 따라 정렬 후 low quality 소스 제거
- 학습 데이터와 테스트 데이터 간 deduplication 진행
2.2 Model Architecture
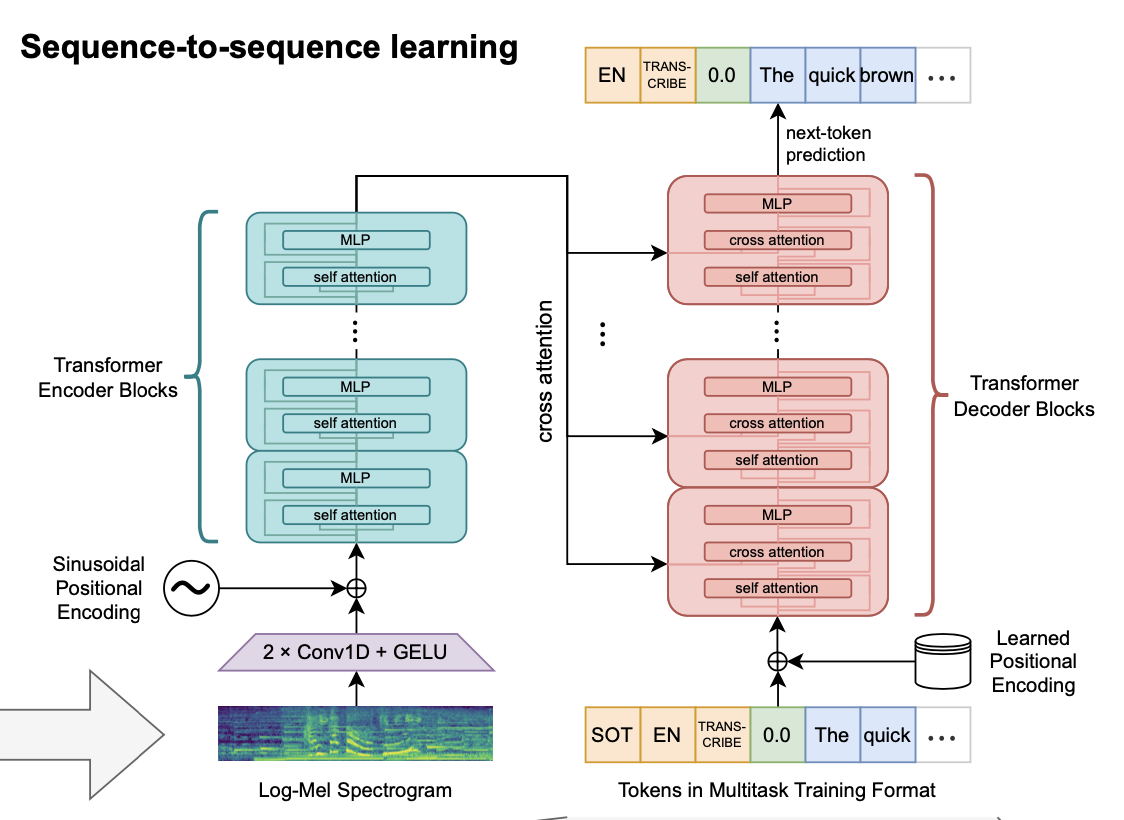
모델 아키텍처: encoder-decoder transformer
Input
- 16,000 Hz, 80 channel log Mel Spectrogram
- 25 millisecond window with a stride of 10 milliseconds
- feature normalization: -1 ~ 1
Log Mel spectrogram
- stft: 음성 데이터를 시간 단위로 쪼개서 FFT(입력신호를 다양한 주파수를 가지는 주기함수로 분해)를 해주는 것
- 주파수를 mel scale로 변환하면 mel filter bank가 나오고 stft한 결과에 곱해주고 dB로 magnitude를 바꿔줌
- 오디오 데이터의 전처리 단계인데 waveform → log-mel spectogram을 뽑고 이를 conv 1D 필터를 씌운 피처를 뽑아서 트랜스포머 인코더에 넣는 것
Encoder
- 2 Conv layers with filter width of 3 + GELU
- Sinusoidal position embedding이 output of the stem에 추가
- 트랜스포머 블럭은 pre-activation residual block 사용
- final layer normalization이 인코더 output에 적용됨
Decoder
- 학습한 position embedding 사용 + input-output 토큰 표현 사용
- 인코더, 디코더는 같은 width와 트랜스포머 블럭 개수 사용
Tokenizer
- byte level BPE 토크나이저 사용(GPT2와 동일)
2.3 Multitask Format 💫
- 보통 음성 모델은 ASR, VAD, SD 등 여러 태스크를 따로 함 → 그럼 시스템이 복잡해짐
- Whisper는 하나의 모델이 전체 파이프라인 담당함
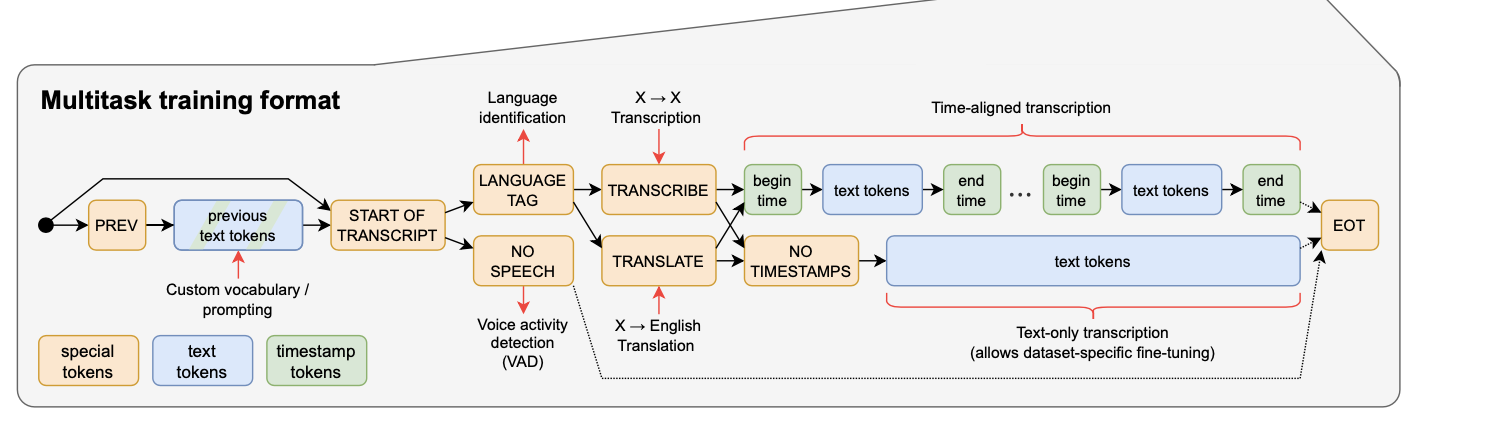
Conditioning information: 디코더에 들어갈 input token을 컨디셔닝
- |Start of Transcript| 토큰으로 추론 시작 나타냄
- 언어 예측 or No Speech
- 태스크 선택: transcribe or translate
- timestamps or No timestamps: 현재 오디오 세그먼트에 상대적인 time을 예측함
- |end of transcript| 토큰으로 추론 끝 알림
Multitask: VAD, Language identification, Transcription, Translation, timestamp prediction
2.4 Training Details
- 다양한 사이즈의 모델 학습
- 학습 환경
- data parallelism across accelerators
- using FP16
- with dynamic loss scaling
- activation check point
- 학습 전략
- AdamW
- gradient norm clipping
- linear learning rate decay to zero
- warm up over the first 2048 updates
- batch size of 256 segments
- 2^20 updates (2-3 passes over the dataset)
- data augmentation 이나 regularization 안 함
Whisper의 이상 행동
- 초기 단계에서 화자 이름을 그럴듯한 틀린 이름으로 예측함
- 원인: 대본에 화자 이름 있는 데이터셋 때문
- 해결: 화자 이름이 안 나오는 일부 대본에 잠깐 fine-tuning함
3. Experiments
Zero-shot evaluation
- 추가학습 없이 다양한 도메인, 태스크, 언어에 대해 테스트
- 여러 데이터셋의 test dataset으로만 테스트
Evaluation Metrics
WER(word error rate)
- WER = (S+D+I)/N
- D: 잘못 삭제된 단어 수, S: 잘못 대체된 단어 수, I: 잘못 추가된 단어 수, N: 정답 텍스트의 단어 수
- WER은 string edit distance를 구하는데 모델 output의 모든 차이를 penalize함 (대본쓰는 스타일이 다른 것임에도 format차이로 높은 error rate 나올 수 있음)
- 이를 해결하기 위해 text normalizer 사용함
- text normalizer 사용으로 WER 거의 50% 감소함
Task-specific results
- English Speech Recognition
- In-the-distribution: 사람보다 AI가 잘 함
- Out-of-distribution: 사람보다 AI가 못 함
- 원인
- AI: 학습 데이터와 테스트데이터의 distribution 비슷(test set을 같은 데이터셋 내에서 held out 방식으로 만드니까)
- 인간: zero-shot test
- Whisper는 이를 극복하고자 함: 다양한 데이터셋/distribution으로 학습
성능 비교
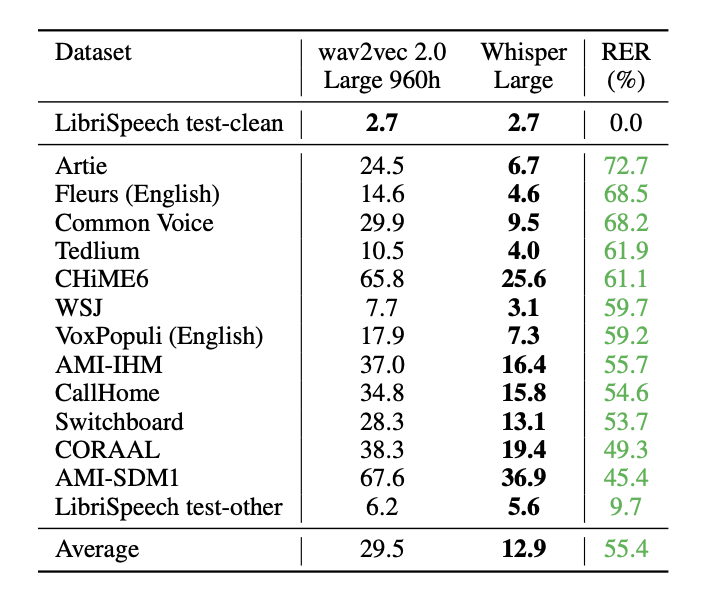
- Multi-lingual Speech Recognition
- Indo-European vs. others: 데이터셋의 대부분이 Indo-European 데이터이기 때문에 Indo-European 언어의 성능이 더 높음
- Translation
- BLEU로 측정
-
Welsh 데이터 라벨링 잘못되어 있던 사례 공유 - 인터넷에서 긁었기 때문에 있을 수 있는 일
-
그래프
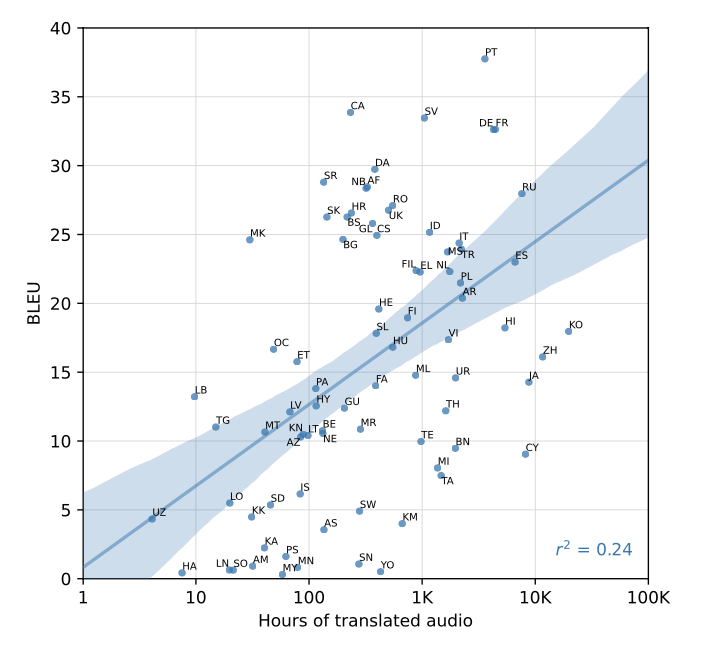
- Language Identification
Fleurs로 테스트했는데 다른 SOTA에 비해 점수 많이 낮음
이유: Fleurs의 102개 언어 중 20 언어가 학습셋에 포함 안 됨
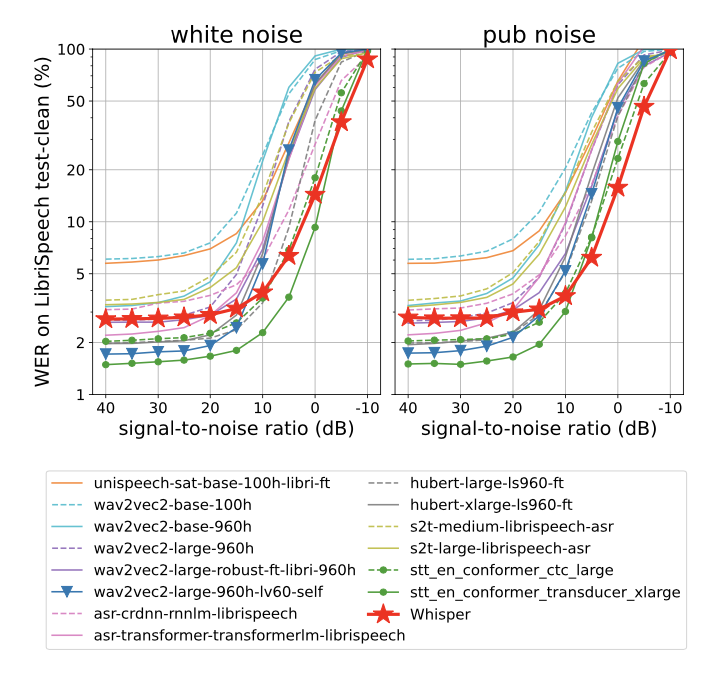
Robustness to Additive Noise
- 데이터에 노이즈를 추가해서 성능 평가함
- white noise & pub noise
-
노이즈가 강해질수록 Whisper가 다른 모델보다 강건한 것으로 나타남
Long-form Transcription
- 30초로 잘라서 학습했기 때문에 한 번에 긴 input을 처리할 수 없음 → 30초로 잘라서 추론
- beam search + temperature scheduling이 성능 향상에 중요
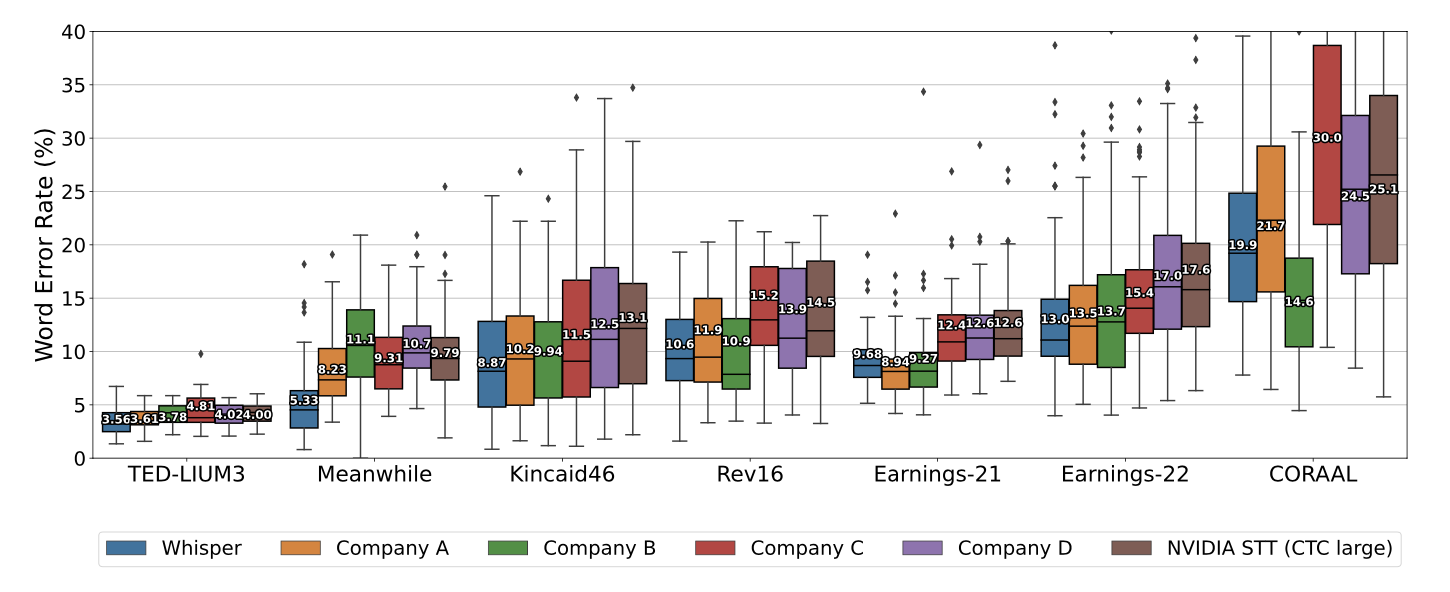
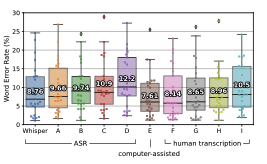
Comparison with Human Performance
테스트를 위해 일부 데이터(Kincaid46 dataset) 선정해서 평가해본 결과 Whisper는 사람과 비슷한 수준
4. Analysis and Ablations
Model Scaling
- Weakly supervised model 이다보니까 더 큰 데이터셋을 사용하고 noiser한 데이터
- saturation 문제
- 데이터셋의 개성을 배우고 일반화 성능이 떨어질 수 있음
- 모델 사이즈로 테스트해본 결과 영어 제외하고 모델 사이즈 늘릴수록 성능 계속 올라감
Dataset Scaling
- 모든 태스크에서 데이터셋 사이즈는 성능과 비례함
- whisper 모델도 under trained 되었다고 볼 수 있어서 더 큰 모델과 더 오랜 학습으로 성능 개선 가능할 수 있음
Multitask and Multilingual Transfer
- 하나의 모델을 multitask, multilingual로 학습할 때 negative transfer 문제 있을 수 있음
- 작은 모델의 경우: negative transfer 있음
- joint model < english only model
- 큰 모델의 경우: multitask, multilingual 모델이 성능 더 좋았음
Text Normalization 💫
- Whisper에 사용한 text normalizer가 whisper에 overfit되었나 테스트
- Whisper과 같이 text normailization을 개발했기 때문에 whisper의 과적합되었을 수 있기 때문에 다른 데이터셋으로 평가
- Fairspeech의 normalizer와 비교함
-
text normalizer 비교
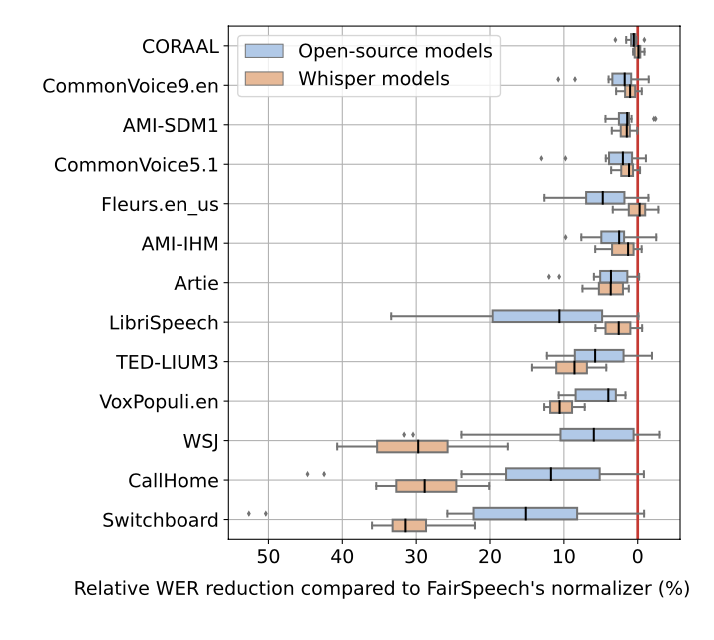
- 13개의 데이터셋에 대해 비교해봤을 때 수치가 많이 나오는 데이터셋의 경우 Whisper을 이용했을 때 성능이 더 좋았음
Strategies for Reliable Long-form Transcription 💫
- 긴 대본을 추론하기 위해 추가한 휴리스틱한 튜닝들
- Beam search w/ 5 beams and log probability as the score function
- Start from temperature 0 → increase by 0.2 to 1.0
-
VAD 개선을 위해 No Speech 토큰 뿐 아니라 no-speech probability가 0.6 이상인 경우도 필터링 - 모델이 초기 단어 무시하는 것을 방지하기 위해 첫 timestamp는 0.0~1.0초 사이로 제한
- Beam search
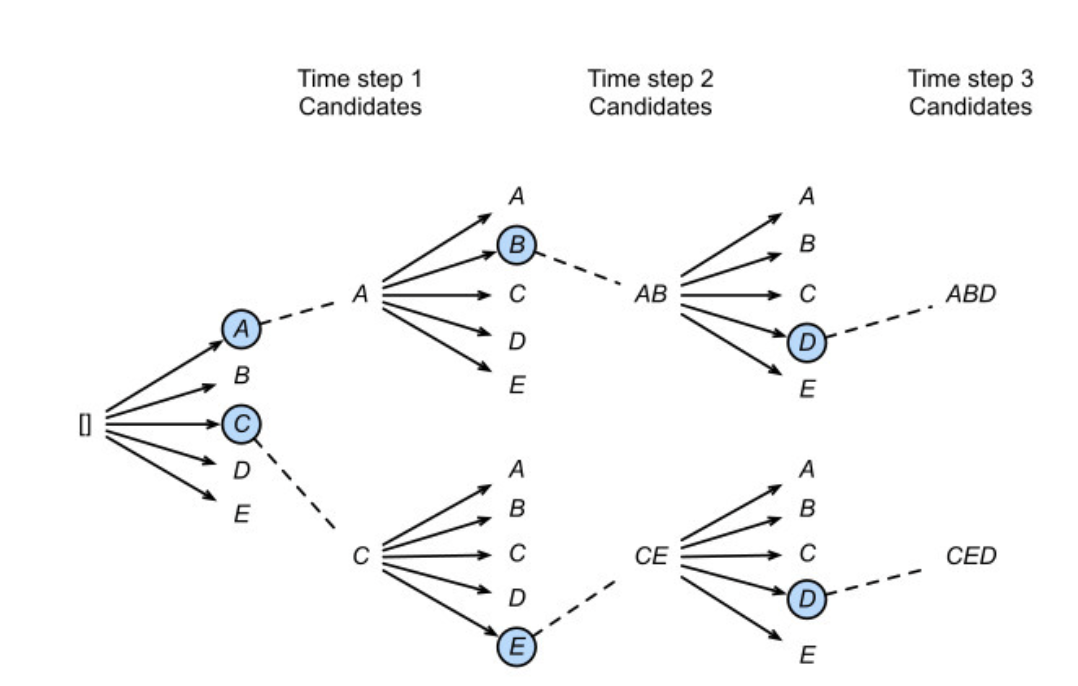
Beam search: beam width 만큼의 토큰을 input으로 넣고 softmax output layer를 거쳐서 beam 개수만큼의 토큰을 예측함. 이렇게 나온 후보들 중 가장 확률 높은 시퀀스 선택
5. Related Work
- Scaling Speech Recognition
- Multitask Learning
- Robustness
6. Limitations and Future Work
Improved decoding strategies
- Perception related error(비슷한 소리 구분) → 모델 크기 키우면 개선 가능
- 하지만 non-perceptual error의 해결은 아직 숙제임
- 이런 에러들은 언어 모델 자체의 문제 때문인데 complete hallucination이나 stuck in repeat loops, 첫 단어나 마지막 단어를 전사하지 않는 문제 등
- 해결 방안 제안: 고품질의 데이터셋으로 학습하거나 강화학습으로 디코딩 개선
Increase Training data for lower-resource languages
- 데이터셋이 대부분 영어로 이루어져 있기 때문에 데이터 불균형이 심함
- 낮은 성능을 보이는 언어의 경우 데이터 추가하는 것이 당연히 성능 향상에 도움이 됨
Studying fine-tuning
- 고품질의 supervised speech data가 존재하면 fine-tuning했을 때 성능이 더 올라갈 것
Tuning Architecture, Regularization, and Augmentation
- 이 논문에서 주력하고자 한 것이 데이터셋 scale up이었기 때문에 이에 집중하고자 최신 기법들이 많이 사용되지는 않았음
- dropout, stochastic depth, data augmentation, SpecAugment 등의 기법과 fine-tuning으로 성능 개선 가능
Adding Auxiliary Training Objectives
- 최신 연구의 흐름인 unsupervised pre-training이나 self-teaching 기법을 사용하지 않았지만 이를 잘 결합하면 성능 개선에 도움이 될 수 있음
7. Conclusion
단순한 방법이지만 더 크고 다양한 데이터셋으로 모델을 학습하는 것과 zero-shot transfer이 모델의 강건함을 개선하는 것을 보여줌
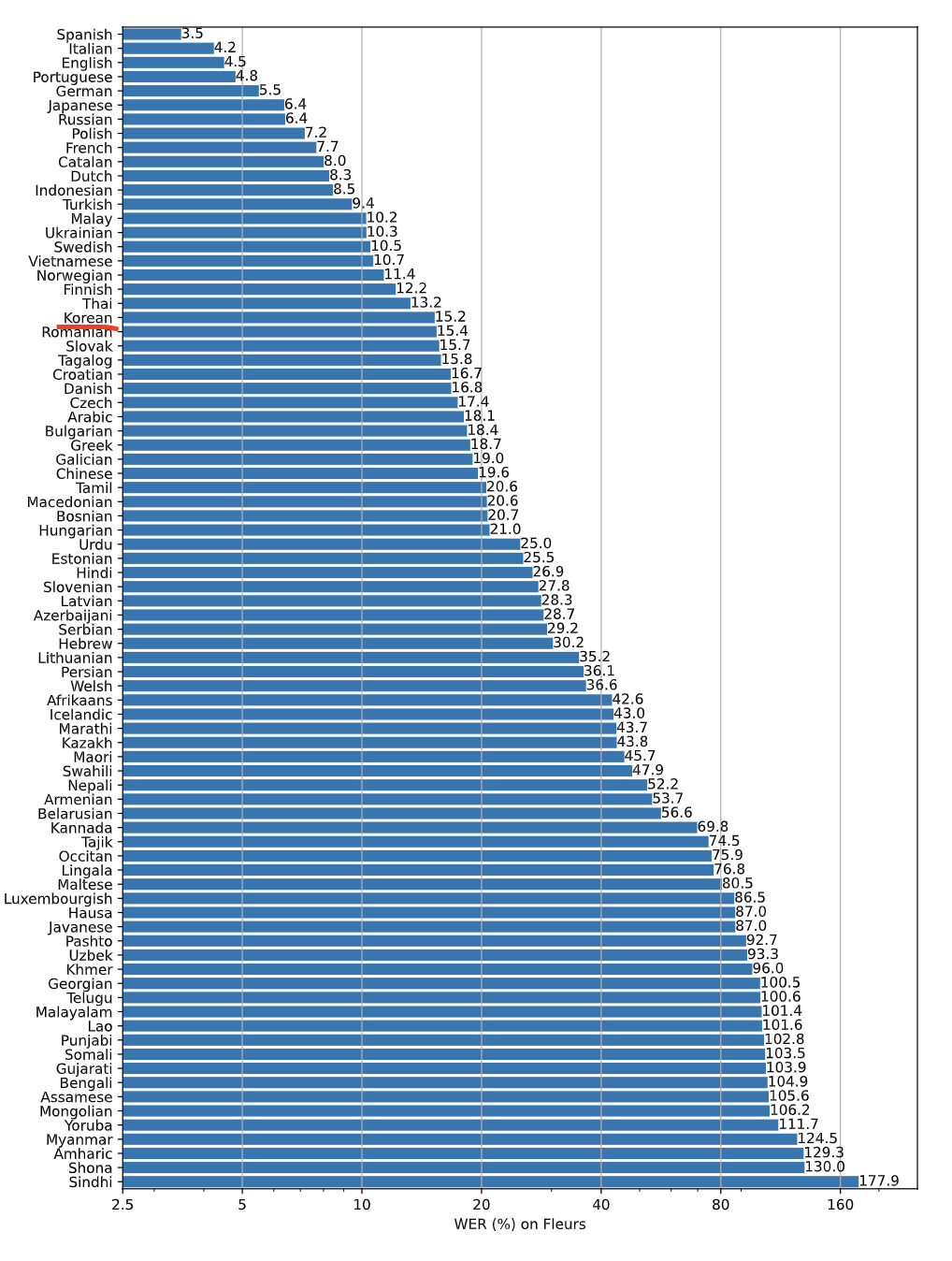
한국어 성능
-
Fleurs 데이터셋 언어별 성능
읽은 후기
다양한 실험 결과와 전처리 과정에 대한 상세하게 설명하고 있는 논문이어서 음성 인식 모델을 만들 때 많은 도움을 받았다. 시간 및 인력 자원의 부족으로 많은 튜닝을 해보기 어려운데 위 논문을 참고해서 공부하고 때때로 필요한 부분을 적용하고 있다. 또한 좋은 성능의 모델 가중치와 코드가 공유되어 있어 사용이 쉽고 한국어 예시가 많이 있어서 내적 친밀감을 느끼기 좋다.